
Author: Cyprian Moye, Cloud Engineer
Introduction
Unmatched agility and efficiency in managing workloads can be achieved by integrating HorizontalPodAutoscaler (HPA) with Kubernetes deployments to ensure seamless performance. HPA can automatically adjust workload resources such as Deployments or StatefulSets, aligning application scaling with demand fluctuations without manual intervention. HPA offers the flexibility to scale resources up or down as needed by automatically adjusting the number of pod replicas based on observed metrics. This can optimize cost, improve resource utilization, and optimize performance among other advantages.
Horizontal vs. Vertical Scaling
Unlike vertical scaling, which involves allocating more resources (e.g., CPU or memory) to existing Pods, horizontal scaling entails automatically deploying additional Pods in response to increased load and scales back down when the load decreases. Horizontal scaling is generally preferred because it ensures enhanced agility and efficiency in managing workload fluctuations by adding or removing pod replicas based on demand. This leads to optimal resource utilization and fault tolerance while simplifying tasks management.
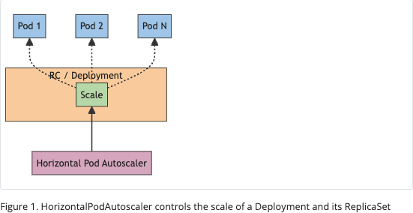
HorizontalPodAutoscaler Implementation
The HPA operates within the Kubernetes control plane and is implemented as a Kubernetes API resource and controller. It periodically assesses target workload metrics such as CPU utilization, average memory utilization or custom metrics specified by the user. By leveraging these metrics, the controller dynamically adjusts the desired scale of the target resource, ensuring optimal performance in response to changing conditions.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
status: observedGeneration: 1
lastScaleTime:
currentReplicas: 1
desiredReplicas: 1
currentMetrics:
- type: Resource resource:
name: cpu
current:
averageUtilization: 0
averageValue: 0
Conclusion
It is important to note that HPA doesn’t apply to objects like DaemonSets, which can’t be scaled dynamically. Regardless, Kubernetes deployments empower organizations to effortlessly scale and manage applications dynamically. By embracing Kubernetes’ declarative model and leveraging its advanced features such as the HPA, businesses can achieve unparalleled agility, resilience, and efficiency in their application deployment practices.
References
- The Linux Foundation: Horizontal Pod Autoscaling: https://kubernetes.io/docs/tasks/run application/horizontal-pod-autoscale/
